
ニューラル ネットワークは「人間の脳神経系のニューロンを数理モデル化したもの」と言われ、今や AI を構築するのになくてはならない技術です。Google 翻訳や画像処理などにも活用され、Android スマホの飛躍的な進歩に貢献しています。本記事では、難しい数式を使わずにわかりやすくニューラル ネットワークを解説し、AI の本質に少しでも迫りたいと思います。
ニューラル ネットワークとは?
「人間の脳神経系のニューロンを数理モデル化したもの」をわかりやすく言い換えれば、「人間の脳を真似て人工的に作られた情報処理のネットワーク」といったところでしょうか。そのようなニューラル ネットワークを概念図で表すと、下記のようなものになります。
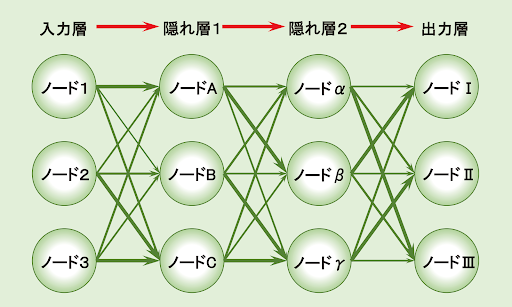
入力層と出力層の間にある「隠れ層」
一見、難しく見える概念図ですが、まずはシンプルに「左の入力層から入った情報が、右へ流れながら少しずつ計算され、出力層から最終的な計算結果が出る」というイメージを持ってください。左端の入力層と右端の出力層の間には「隠れ層」があり、これが複雑なふるまいをすることで人間の脳のような働きをします。
各層は複数の「ノード(●の部分)」で構成され、各ノードは「エッジ(矢印)」で結ばれています。隠れ層 1 の「ノード A」を見ると、前の層の「ノード 1~3」のすべてから情報を受け取って計算し、次の層の「ノード α~γ」のすべてへ計算結果を渡しています。このように、それぞれのノードは基本的に前後のすべてのノードと結ばれています。
この概念図では各層には 3 つのノードしかなく、隠れ層も 2 つしかありませんが、実際のニューラル ネットワークではノードも隠れ層ももっと数が多く、それらが幾重にも結ばれることで最終的な計算結果の精度が高まります。
ちなみにニューラル ネットワークの隠れ層が 2 層以上のものを「ディープ ニューラル ネットワーク」と言い、ディープ ニューラル ネットワークを用いた学習を「ディープ ラーニング」と言います。

矢印の「重み」の違いが重要ポイント
隠れ層 1 の「ノード A」に焦点をあてると下記のようになります。前の層の「ノード 1~3」から入ってくるエッジの太さや、次の層の「ノード α~γ」へ出ていくエッジの太さが、それぞれ異なっていることにお気づきでしょうか。

実は、ノードから入ってくる数値はノードの出力値そのままではなく、それぞれ異なる係数が掛けられ、影響度に違いが出るようになっています。これをニューラル ネットワークでは「重み」と言います。
概念図では、その「重み」を矢印の太さで表し、太い矢印を通ってくる数値には大きな係数が、細い矢印を通ってくる数値には小さな係数が掛けられることを意味しています。もちろん大きな係数であるほど、影響力も大きくなります。概念図の例であれば、ノード A が最も強い影響を受けるのはノード 1 で、最も強く影響を与えるのはノード β となります。
この「重みの違い」こそがニューラル ネットワークの重要なポイントです。なぜなら「重み」が変われば最終結果が変わるため、何度も何度も「重み」を調整しながら学習することで、正答率の高い最終結果を導き出せるからです。

学習を繰り返し最適な「重み」を決める
画像処理を例にとって、もう少し具体的にご説明しましょう。たとえば「乗り物」の画像を見せて、その画像が「飛行機」か「船」か「車」か、判断させたいとします。
1 枚の画像データはピクセル(画素)で構成されており、そのピクセルの 1 つ 1 つが数値化できる情報を持っています。ただし実際の画像はかなり多くのピクセルで構成されているため、さまざまな前処理で画素数を落とします。仮に 1000 ピクセルまで落とした場合、1 ピクセルを 1 つのノードに入力するため、入力層に 1000 個のノードを持ったニューラル ネットワークになります。
出力層のノードは「飛行機」、「船」、「車」の 3 つになります。ただし出力層の手前で、合計を 100%にしてくれる「Softmax(ソフトマックス)関数」などを用いて、最終的に出力される数値は確率値になるようにします。たとえば「飛行機である確率は 60%、船である確率は 30%、車である確率は 10%」というようなものです。
こうしておいて、飛行機の画像データをニューラル ネットワークに入力します。ニューラル ネットワークはひたすら計算し、それぞれの乗り物である確率を出しますが、もともと飛行機の画像データを入力しているので、最終結果は「飛行機である確率は 100%、船である確率は 0%、車である確率は 0%」になるのが理想です。
そこでエッジの「重み」を 1 つ 1 つ調整したり、他の飛行機の画像を入力したりする学習を重ねて、飛行機である確率が 100% に近づくように精度を高めていくのです。ただし、完全に 100% になるところまで追い込むことはしません。「過学習」と言って、学習のし過ぎによる弊害が出てくるからです。学習に使ったデータでは完璧な答えを出しますが、それ以外の新しいデータが入力されたとき、上手く対処できなくなるのです。
エッジの数は非常に多いため、その計算量は膨大なものになります。ただ、ひたすらトライ アンド エラーを重ねて学習を進めるのではなく、誤差逆伝搬法(正解値との誤差を元に、前の層、その前の層と、逆に遡ってエッジの重みを修正していく方法)など、さまざまな手法に基づいて効率的かつ自動的に行われていきます。
このように膨大な数の学習を重ねることで、ニューラル ネットワークは人間の脳に近づいていくのです。

言語でも活躍するニューラル ネットワーク
前項ではニューラル ネットワークの基本的な概念をご説明しましたが、人間が日常的にやりとりする言語を扱う場合には、どのような仕組みになっているのでしょうか。人間の自然な言語を機械で処理することを「自然言語処理(NLP : Natural Language Processing)」と言い、ここではその解説をしたいと思います。
単語をベクトル化して「数値」に変える
ニューラル ネットワークはすべて数値で処理されるため、言語を扱う場合にも、単語をすべて数値化しなければなりません。「単語の数値化」と聞いて、誰もが真っ先に思いつくのが「単語に通し番号をつける」ということでしょう。しかし、それだけでは数値そのものが意味を持たないため、応用が効きません。
そこで「単語のベクトル化」という方法が考え出されました。ベクトルとは「独立した数字の組み合わせ」を意味しています。たとえば、リンゴ、トウガラシ、レモン、バナナ、ピーマン、キュウリをベクトル化してみましょう。この 6 つの違いは「色」と「丸さ」で区別できるため、「色指数」と「丸さ指数」として数値化します。
「色指数」は、虹の 7 色(赤、橙、黄、緑、青、藍、紫)で、完全な赤を 1 とし、完全な紫を 0 とし、「丸さ指数」は、完全な球形を 1 とし、針のように細長いものを 0 とします。この法則で、たとえば「キュウリ」を数値化すると、色指数は赤と紫の間にある緑なので 0.5、丸さ指数は針ほどではなくても細長いので 0.2 というような具合でしょうか。このような方法で 6 つをすべて数値化し、「色指数 , 丸さ指数」で表すと、下記のようになります。
- リンゴ (0.9 , 0.9)
- トウガラシ(0.9 , 0.1)
- レモン (0.7 , 0.6)
- バナナ (0.7 , 0.3)
- ピーマン (0.5 , 0.5)
- キュウリ (0.5 , 0.2)
なお、ベクトルの数字が何種類あるか、その数のことを「次元」と言います。この例の場合は「色指数」と「丸さ指数」の 2 種類だけですから「2 次元ベクトル」です。
しかし実際は 2 次元ベクトルで収まるはずもありません。たとえば、これだけの指数ですと「赤で丸いリンゴ」と「赤で丸いトマト」を区別するのは難しいですよね。そこで、固さや甘さなどさまざまなベクトルを追加していかなければなりません。
この世には、非常に多くの単語が存在します。しかも名詞だけではなく、動詞や形容詞などもあります。一体、何次元が必要なのでしょうか? 何を指数にすればよいのでしょうか? どのような法則で計算したらよいのでしょうか?
実は、これらはニューラル ネットワークによって自動的に決められるのです。「リンゴ」の例では、こちらが「色指数」や「丸さ指数」を決めましたが、実際のアルゴリズムでは AI が学習の過程で自由に指数を決めていきます。つまり私たち人間は、最初に大枠のプログラムを組むものの、最終結果に至った過程や理由を知ることができません。
しかし、よくよく考えてみれば、私たち人間も、なぜ自分がリンゴを見てリンゴと判断するのか、うまく説明できません。そういった意味でも、AI は人間に近づいてきているのでしょう。

文章の計算は「虫食い状態」で学習
「文章」は、単語の羅列と考えることができ、個々の単語に分解できます。しかし日本語は、単語と単語の間に区切りのスペースがないため、英語などスペースのある言語に比べると、この分解にも一手間かかってしまいます。
その手間をクリアすると、たとえば『私は毎日学校で勉強する』は、『私 は 毎日 学校 で 勉強 する』に分解されます。ニューラル ネットワークに学習させるときは、わざとテスト問題のように『学校』だけを抜いて、『私 は 毎日 〇〇 で 勉強 する』と虫食い状態にします。
ニューラル ネットワークは『〇〇』を求めるために、「隠した単語の近くには関係の深い単語があるだろう」という推測で、近い単語のベクトルから計算していきます。正解は『学校』とわかっているので、答え合わせをしながらニューラル ネットワークのエッジの重みを調整することを何度も何度も繰り返し、最終的に『学校』のベクトルを得ることができます。このような学習を繰り返し、すべての単語のベクトルを獲得していくのです。

「文章全体」を同時に並列処理して性能アップ
2017 年に Google が発表した「トランスフォーマー(Transformer)」は、自然言語処理能力を飛躍的に高めることに成功しました。ここでは、トランスフォーマーの仕組みとそれに関連する手法について、簡単に触れておきます。
トランスフォーマーでは、それまでの文章を頭から順に計算処理していく逐次処理型の「RNN(Recurrent Neural Network)」などとは異なり、並列処理で「文章全体」を同時に扱っていきます。並列処理なら、行列計算や画像の計算処理を行う半導体チップである「GPU(Graphics Processing Unit)」などを効率的に利用できるので、大幅な高速化が実現可能です。
また、並列処理によって文章内での単語の順番の情報が欠落するのを防ぐため、文章内での「位置情報」を付与する(Positional Encoding)など、さまざまな工夫を凝らしています。
なお、前項では「単語は近くの単語と関連性が深い」という前提のもとに単語の計算や学習をしていましたが、実際の文章では遠く離れた単語同士でも結びつきが強い場合があります。それを取りこぼさないために「アテンション(Attention)」という考え方を導入し、どの単語に注目すればよいか、その重要度も数値化して計算しています。

機械翻訳に革命をもたらしたトランスフォーマー
トランスフォーマーによって、自然言語処理の応用である「機械翻訳」の精度が革新的に向上しました。ここでは、トランスフォーマーが実際どのようにして「翻訳」をするのか、見てみましょう。
たとえば、日本語の『私は英語を勉強する』を英語に翻訳すると『I study English』ですが、これを簡単に図解すると、下記のようになります。なお、図の中に「AI 語」とありますが、これは専門用語ではなく比喩的な表現で、わかりやすくするために使っています。

トランスフォーマーは大きく分けると、エンコーダー(Encoder)とデコーダー(Decoder)という 2 つのブロックから成ります。
まず、エンコーダーに日本語の『私は英語を勉強する』が入力されます。エンコーダーの役目は、簡単に言えば「日本語」をベクトル化し「AI 語」に変換することです。ここでのベクトル化は、前項で解説した単語だけではなく、文章全体もベクトル化しています。
一方、デコーダーの役目は、その「AI 語」を再び人間の言語に戻すことです。この場合は「英語」に翻訳するので、「AI 語」を「英語」に変換して、最終的に『I study English』を出力します。
トランスフォーマーの「エンコーダー」とは?
エンコーダーの中で行われていることを、かなり簡略化して説明すると、下記のようなステップになります。
【1】ベクトル化
エンコーダーに『私』『は』『英語』『を』『勉強』『する』の 6 単語が入力されます。最初に 6 単語の「ベクトル化」が行われ、それぞれ「512 次元ベクトル」に変換されます。
【2】位置情報の付与
ポジショナル エンコーディング(Positional Encoding)という層で、それぞれのベクトルに元の単語の「位置情報」が付与されます。「その単語が文章の前から数えて何番目か」の情報ですが、実際には三角関数を用いた計算で位置情報が与えられます。
【3】アテンションの計算
次のステップは、いよいよトランスフォーマーの特徴である「アテンション(Attention)」です。単語同士の意味的な距離(関わり合いの深さ)を計算し、情報をベクトルに盛り込んでいきます。なお、ここでのアテンションは、一つの文章の中に含まれた単語同士で距離を計算するので、「セルフ アテンション(Self Attention)」と言います。
この処理層は、実際には「マルチヘッド アテンション(Multi-Head Attention)」という仕組みになっています。初期設定が異なる複数のニューラル ネットワークを使って同時にセルフ アテンションの計算をさせ、最後に結果を統合するのです。多角的な視点で計算するというイメージでしょうか。さらに、この処理を何度も繰り返すことで、言語処理の精度を一層高めています。
ここではその他に、Add & Normalize や Feed Forward などの補助的な計算も行われます。そして最終的に、元の単語の情報に加え、位置情報、単語間の意味的な距離など、さまざまな情報を含むベクトルの集合体である「AI 語」となるのです。

トランスフォーマーの「デコーダー」とは?
デコーダーもエンコーダーとよく似た構造なのですが、アテンションの計算は 2 段階あるため、第 1 段階、第 2 段階と呼ぶことにすると、下記のようなステップになります。
【1】ベクトル化
【2】位置情報の付与
【3】アテンションの計算 第 1 段階
【4】アテンションの計算 第 2 段階
エンコーダーから受け取った「AI 語」を、まずは【1】ではなく【4】のステップで処理し、最初の単語を決める計算をします。デコーダーはすでに内蔵している英単語のボキャブラリーの中から、この翻訳英文の最初に来る確率が最も高い単語を選んで出力します。この場合だと、『I study English』の『I』がまず出力されるでしょう。
その『I』を【1】に戻してベクトル化し、【2】で位置情報を付与し、【3】で『I』と関わり合いの深い単語を探します。【4】では【1】~【3】までの計算と、エンコーダーから受け取った「AI 語」のベクトルも参照しながら単語同士の関わり合いを計算します。
つまり【4】では、デコーダーの計算による「英語の単語」と、エンコーダーからの「AI 語の単語(元は日本語)」との間の「関わり合い」も計算するのです。これは、同一文章内で参照し合う「セルフ アテンション」に対し、異なる系列のデータを参照するという意味で「ソース ターゲット アテンション(Source-Target Attention)」と言います。これらの情報を総動員して計算し、デコーダーは『I study』という文章を出力します。
そして『I study』を【1】に戻し、『I』と『study』を並列処理でベクトル化し、【2】で位置情報を付与し、【3】で『I』と『study』に関わり合いの深い単語を探します。そして【4】で「AI 語」との意味的距離も参考にしながら、この後ろに来る確率が最も高い単語、『English』を選び、『I study English』を出力します。
さらに『I study English』を【1】に戻して、また同じ処理がなされますが、今度は「どうもこれで文章が終わる確率が高い」と判断され、「EOS(End Of Sentence)」という特別なコードが出力されて、翻訳が完了します。
なお、エンコーダーと同様に、アテンションの第 1 段階、第 2 段階も「マルチヘッド アテンション(Multi-Head Attention)」であり、複数の並列ネットワークでアテンションを計算して統合し、またそれを何度も繰り返して精度を高めています。
途中のベクトル計算は複雑なように感じますが、基本は行列演算の繰り返しであり、それを実行するのはニューラル ネットワークです。高い精度の翻訳を実現するためには、その前に膨大な「機械学習」が必要なのは言うまでもありませんが、ここでもトランスフォーマーの並列計算による「速さ」が威力を発揮します。
以上、Add & Normalize や Feed Forward なども省略し、かなり簡略化したものではありますが、トランスフォーマーの大まかな流れについて解説しました。

Google が誇る BERT は「文脈」の流れも理解
2018 年に Google が発表した BERT(バート: Bidirectional Encoder Representations from Transformers)は、自然言語処理において革新的なものでした。BERT は、前項で触れたトランスフォーマーのエンコーダーを多段階的に接続したものです。「Bidirectional(バイディレクショナル)」は双方向の意味ですが、BERT では文章の前後の双方向から文脈をつかむことができます。
これを実現するための学習方法は独創的です。1 つは、MLM(Masked Language Modeling)。「穴埋め問題」式の学習法ですが、問題を準備するのに学習用の文章からランダムに単語を選び、80% の確率で Mask し(隠し)、10% の確率で他の単語へランダムに置き換え、10% の確率で元の単語のままにするという、手の込んだ「問題作り」をして学習を繰り返します。
もう 1 つは、NSP(Next Sentence Prediction)。文章同士の結びつきを学習するもので、問題を準備するのに文章を A と B の 2 つ用意しますが、A と B をつなげて意味が通るパターン(今日は雨です。傘をさします)と、意味がないパターン(今日は雨です。ボールを投げます)を 50% ずつ与えることで、文章同士の関係性を学習させます。
このように工夫を凝らしたさまざまな学習をニューラル ネットワークに繰り返させることで、人間が日常的に使う自然な言語へと近づけています。

手のひらで感じる Android スマホの進化
ニューラル ネットワークについて数式を使わずに解説しましたが、いかがでしたか。画像処理や自然言語処理には複雑かつ膨大な計算を要しますが、ニューラル ネットワークは何度も計算を繰り返して学習し、正しい答えを導き出していることがおわかりいただけたことでしょう。
実はニューラル ネットワークのアイデアそのものは古くからありましたが、実用レベルの翻訳などへの本格利用は、ハードウェア、つまり CPU や周辺チップの驚異的な性能向上によって初めて可能となりました。
そして今や、Android スマホ単体でもできるようになったのです。Google Pixel 6 に搭載された Google 独自開発の Tensor(テンソル)に代表されるように、目的に合わせて最適化された高速低消費電力チップセットをスマホに搭載することで、外部に接続することなく高度な画像処理や自然言語処理を実現しています。
このように大いなる可能性を秘めた Android スマホを手のひらにのせ、ビジネスやプライベートのさまざまなシーンで、自分らしくスマートに活躍しましょう。
※本記事で紹介した内容は、執筆時(2022年8月)のものです。

Android スマホの即時的な自動翻訳とは? 会話はもちろん写真や動画まで即座に翻訳する驚きの実力!


2025年12月04日
2025年12月04日

